A survey of open APIs
I did some research in the past week on a few “Open APIs”, and wanted to share my findings here. This is just a summary of other, more comprehensive sources. Also, if you have any comments or corrections I’d love to hear them. I chose to present my findings as a list of concepts:
The Open Stack
This is an emerging stack of open protocols that will help build socially-connected websites. I will explore the key elements (I take XRDS-Simple to be rather low level and uninteresting).
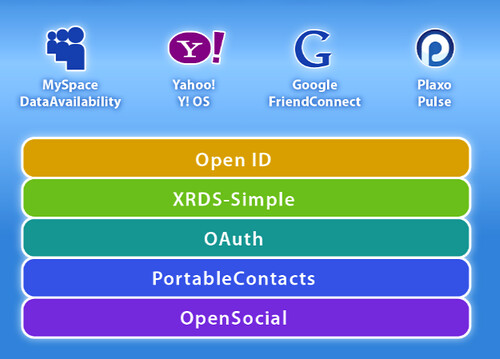
OpenID
- A single sign-on protocol (help to user not to create yet another set of user/pass)
- Essential Workflow (here in more details):
- You want to logon to StackOverflow, which is an OpenID Consumer
- Instead of opening yet another account you are given an alternative (almost no site relies solely on OpenID).
- You either enter a URL (way less user friendly) or select from a fixed subset of Providers
- You are redirected to that URL, enter your credentials there (only if you are not logged in), and are asked to allow StackOverflow access to your OpenID identity.
- Depending on your OpenID provider, you can set for how long this access is granted
- Then, you are redirected back to StackOverflow, with a token (encoded in the URL), that is used to grant you access.
- OpenID is mostly still just a login method today (doesn’t convey extra information beyond a logon grant) – although I did see some evidence to the contrary when I just opened an OpenID account at VeriSign – it seems websites can request more information from an OpenID provider – such as email, nickname and full name.
- Microsoft, Yahoo, Google are now OpenID providers (in addition to more veteran providers). This is significant because it doesn’t force users to go to yet another place to open an OpenID account – they can just use an existing webmail account.
- Facebook just joined OpenID foundation board (eBay is there already). Looks like it will become an OpenID provider, maybe also client.
- Users are still not comfortable with it / unable to figure it out.
- However, here is an interesting post about using email addresses as OpenID. When this happens, it might help bring in the users.
- Here is a recipe to enable OpenID on a website (Consumer). Sample Provider implementation for .NET is here.
- Of course, for your WordPress blog the process is much easier – just install OpenID plugin.
- Although, I heeded Tomer’s advice and instead used OpenID delegation – this means I use my blog’s URL as my OpenID, but it is just a redirect to a more serious OpenID provider. OpenID is/will be the keys to your world – better guard them safely.
- Right now, the value of OpenID to a new website is still limited:
- Will not eliminate the need for us to implement user logon
- Not much value in being an OpenID Provider – it’s a nice to have feature, but in many cases not worth the cost (at least until you get a large user base).
- Is not sufficient, on its own, to get access to complete profile information about users (and use this data to help users interact with your website). But … can be complemented with more technologies.
- Has a nice usage graph.
Google OpenSocial
- A set of social APIs developed by Google (get list of friends, publish stories).
- Implemneted y hi5, LinkedIn, MySpace, orkut, Yahoo!, Friendster (full list at the OpenSocial wiki)… but not Facebook (yet). All of these are OpenSocial Containers – data warehouses that answer OpenSocial queries.
- OpenSocial is Open. The data is not stored on Google – the providers just conform to the OpenSocial API which reflects the data stored at each social network.
- Had theoretical reach (not usage!) of 700M users Nov 08.
- To serve OpenSocial:
- You can use Shindig (java), implement a few interfaces to tie it to your own data model.
- Here is an SDK for eclipse and an easy to follow PDF can be found here.
- I did not find an active .NET implementation! (Found two libraries, version 0.1, not much usage).
- Client implementations are available in javascript, java, .net, php, whatnot…
Google FriendConnect
- An application that uses OpenSocial to enhance websites with social widgets (Comments, Reviews, …).
- Is still not wildly spread (this directory is rather sparse at the moment)
- Doesn’t seem to be targeted at big sites, rather at small sites/blogs (my impression at least).
- No programming required to add social features to your site – but you have limited control over the effect.
- Cool flow I tested: Login to FriendConnect on a website, and you already see in your friends list a buddy from Gmail that’s using FriendConnect at this site.
OAuth
- A standard for securing access to APIs (access control).
- Usages are very varied – can be used for any API – publishing tweets, getting contacts, commenting on blogs, upload images to PhotoBucket.
- There is still huge untapped potential here.
- Used by Twitter, Google (data API), Yahoo, MySpace … full list of providers.
- Libraries in C#, java, php, more…
Portable Contacts
- API to retrieve list of email contacts (draft spec can be found here, JSON/java implementation at Google labs).
- This is meant to replace scraping – users should never again give their email password to a 3rd party website.
- Currently not standard (proprietary equivalents are Google Contacts API, Yahoo Address Book and Live Contacts API).
- But … it is coalescing slowly.
- Uses OAuth for authentication.
- Might integrates with OpenID – a user can be redirected to Google for a federated/simultaneous sign-on + contact fetching.
Facebook Connect
- Competitor of the open stack (OpenID+OpenSocial) – gives single sign-on + connects you to Facebook friends & feed
- Uses a popup instead of redirecting to FB (less intimidating for users).
- Has already been witnessed to boost new user signup.
- Main Flow:
- User clicks Connect

- Popup (in facebook.com) asks user to confirm
- User is shown a Presence Indicator at the target site

- Website can pull user’s profile & connections.
- Publish stories to Facebook.
- Send Facebook hashes of emails, and Facebook replies if they have a user with an identical hash. This can be used to show a user a count of his Facebook buddies that are using the target site (“10 of your friends are using this site, connect to Facebook now”).
- User clicks Connect
- Example of a FB connect-enabled site – TheRunAround.
RPX / JanRain
- JanRain – An early OpenID player (in the market since 2005, one of the founders of OpenID).
- RPXNow – abstracts away Single Sign-on, supports both Facebook Connect and major OpenID players.
- Here is a blog post about why not to use it (Vendoer lock-in, single point of failure, too little benefit).
- However, check out the counter arguments in the comments.
- RPX get social profile data from Google, MySpace, Facebook.
- This includes interesting profile fields like email/gender/birthday/photo.
- The API also hints at getting an array of friends from relevant services.
That’s it for now, I hope you enjoyed this review. Remember that most of these APIs are very new or just being adopted, so expect changes to most of these. I expect a large API convergence to happen in the following year or two, which will simplify life for those of us building social applications.



