6/4/15, 21:22
I would like to introduce you to Synereo, the world’s first fully decentralized, attention-based social network.
I wrote before about the need for a decentralized internet, which is rapidly being built. Synereo is building the social networking platform for that model. One important difference between them and other decentralized open source social networks (Diaspora anyone?) is that Synereo has an internal tradeable token that can be used to monetize the network, fund development, and attract users (free amps anyone?)
In a world where users are products, Synereo’s model turns users into active agents that get rewarded for the actions, content and attention.
I haven’t had the chance to really dig into their model or tech stack, although I know and highly appreciate the founder. The tech isn’t really ready yet, they are just raising funds now (the sale of ‘amps’ ends in 16 days).
* Disclaimer – I am not invested in Synereo, nor do I own any ‘amps’.
16/7/10, 0:51
I’m following his lead and integrating Facebook’s Like button in this blog.
16/4/09, 15:13
I’ve been playing around with Facebook Apache Thrift recently. I had a tough time finding working Thrift binaries for win32, and the compilation process was not trivial, so I’ve decided to put them online.
So here they are, compiled with cygwin from Thrift 0.1.0. This will probably require cygwin to run (remember to add cygwin binary directory to your path).
Note, the compilation process created two different files named thrift.exe – one small (16kb) file and the larger 10mb file I’ve put online (this one actually works).
27/3/09, 2:19
I did some research in the past week on a few “Open APIs”, and wanted to share my findings here. This is just a summary of other, more comprehensive sources. Also, if you have any comments or corrections I’d love to hear them. I chose to present my findings as a list of concepts:
The Open Stack
This is an emerging stack of open protocols that will help build socially-connected websites. I will explore the key elements (I take XRDS-Simple to be rather low level and uninteresting).
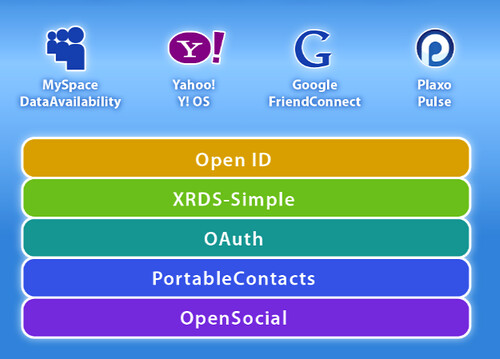
OpenID
- A single sign-on protocol (help to user not to create yet another set of user/pass)
- Essential Workflow (here in more details):
- You want to logon to StackOverflow, which is an OpenID Consumer
- Instead of opening yet another account you are given an alternative (almost no site relies solely on OpenID).
- You either enter a URL (way less user friendly) or select from a fixed subset of Providers
- You are redirected to that URL, enter your credentials there (only if you are not logged in), and are asked to allow StackOverflow access to your OpenID identity.
- Depending on your OpenID provider, you can set for how long this access is granted
- Then, you are redirected back to StackOverflow, with a token (encoded in the URL), that is used to grant you access.
- OpenID is mostly still just a login method today (doesn’t convey extra information beyond a logon grant) – although I did see some evidence to the contrary when I just opened an OpenID account at VeriSign – it seems websites can request more information from an OpenID provider – such as email, nickname and full name.
- Microsoft, Yahoo, Google are now OpenID providers (in addition to more veteran providers). This is significant because it doesn’t force users to go to yet another place to open an OpenID account – they can just use an existing webmail account.
- Facebook just joined OpenID foundation board (eBay is there already). Looks like it will become an OpenID provider, maybe also client.
- Users are still not comfortable with it / unable to figure it out.
- However, here is an interesting post about using email addresses as OpenID. When this happens, it might help bring in the users.
- Here is a recipe to enable OpenID on a website (Consumer). Sample Provider implementation for .NET is here.
- Of course, for your WordPress blog the process is much easier – just install OpenID plugin.
- Although, I heeded Tomer’s advice and instead used OpenID delegation – this means I use my blog’s URL as my OpenID, but it is just a redirect to a more serious OpenID provider. OpenID is/will be the keys to your world – better guard them safely.
- Right now, the value of OpenID to a new website is still limited:
- Will not eliminate the need for us to implement user logon
- Not much value in being an OpenID Provider – it’s a nice to have feature, but in many cases not worth the cost (at least until you get a large user base).
- Is not sufficient, on its own, to get access to complete profile information about users (and use this data to help users interact with your website). But … can be complemented with more technologies.
- Has a nice usage graph.
Google OpenSocial
- A set of social APIs developed by Google (get list of friends, publish stories).
- Implemneted y hi5, LinkedIn, MySpace, orkut, Yahoo!, Friendster (full list at the OpenSocial wiki)… but not Facebook (yet). All of these are OpenSocial Containers – data warehouses that answer OpenSocial queries.
- OpenSocial is Open. The data is not stored on Google – the providers just conform to the OpenSocial API which reflects the data stored at each social network.
- Had theoretical reach (not usage!) of 700M users Nov 08.
- To serve OpenSocial:
- Client implementations are available in javascript, java, .net, php, whatnot…
Google FriendConnect
- An application that uses OpenSocial to enhance websites with social widgets (Comments, Reviews, …).
- Is still not wildly spread (this directory is rather sparse at the moment)
- Doesn’t seem to be targeted at big sites, rather at small sites/blogs (my impression at least).
- No programming required to add social features to your site – but you have limited control over the effect.
- Cool flow I tested: Login to FriendConnect on a website, and you already see in your friends list a buddy from Gmail that’s using FriendConnect at this site.
OAuth
Portable Contacts
Facebook Connect
- Competitor of the open stack (OpenID+OpenSocial) – gives single sign-on + connects you to Facebook friends & feed
- Uses a popup instead of redirecting to FB (less intimidating for users).
- Has already been witnessed to boost new user signup.
- Main Flow:
- User clicks Connect

- Popup (in facebook.com) asks user to confirm
- User is shown a Presence Indicator at the target site

- Website can pull user’s profile & connections.
- Publish stories to Facebook.
- Send Facebook hashes of emails, and Facebook replies if they have a user with an identical hash. This can be used to show a user a count of his Facebook buddies that are using the target site (“10 of your friends are using this site, connect to Facebook now”).
- Example of a FB connect-enabled site – TheRunAround.
RPX / JanRain
- JanRain – An early OpenID player (in the market since 2005, one of the founders of OpenID).
- RPXNow – abstracts away Single Sign-on, supports both Facebook Connect and major OpenID players.
- Here is a blog post about why not to use it (Vendoer lock-in, single point of failure, too little benefit).
- However, check out the counter arguments in the comments.
- RPX get social profile data from Google, MySpace, Facebook.
- This includes interesting profile fields like email/gender/birthday/photo.
- The API also hints at getting an array of friends from relevant services.
That’s it for now, I hope you enjoyed this review. Remember that most of these APIs are very new or just being adopted, so expect changes to most of these. I expect a large API convergence to happen in the following year or two, which will simplify life for those of us building social applications.
Tags:
APIs,
Facebook,
Facebook Connect,
FriendConnect,
Google,
Microsoft,
OAuth,
Open Source,
Open Stack,
OpenSocial,
Portable Contacts,
Programming,
RPX,
Social
Comments Off on A survey of open APIs
13/2/08, 11:41
Like or not, I find myself using Facebook, reading stories and rating articles “I Like” or “Dislike”. I would rather read this feed in my RSS feed then log into FB constantly, but then I lose the ability to rate stories.
How about a supplement to the RSS standard which would allow a user to vote on/rate articles, tag them (not just locally in his feedreader), and generally send information back to the RSS info supplier? I’m guessing this might benefit both content supplier and user. In said Facebook example, today if I have a smart enough RSS reader maybe I can rate articles, but this rating is separate from Facebook’s internal rating system.
9/1/08, 20:01
Courtesy of Eran
Since everybody seems to accept/invite to all kind of stupid things:
Facebook Spyware App
13/12/07, 18:42
After some posts containing only links I thought I’d update a bit on other recent events:
1. LAN Party at Oren’s place. Great games of Starcraft and UT. I still hold it again Zelner for dropping out 2 minutes after the start of a game, where him, his brother and I were against 4 players. That left only Ari and me vs the other four players. We fought bravely, but lost as expected. This was the first LAN party in which I actually somewhat enjoyed a game of Call of Duty. Next party should be held sometime after Starcraft 2 and UT3 are out.
2. A week of diving in Eilat with the family. Well, we dived only a small portion of the week due to the cold water running nose. Aya started her 1st star diving course, but unfortunately failed to complete it because of an ear infection. BTW, except for weekends, Eilat is a ghost town in the winter (and with good reason :).
3. In January I’m going to snowboard in France for 8 days, with Jonathan, Pisnoy and more.
4. A small breakthrough with my thesis. After about a month of being stuck, I managed to prove something 🙂 Huzza for me.
5. I joined Facebook, but am still very neutral/ignorant towards it. Luckily I refuse to install any applications or causes. I do like its image tagging mechanism though.
That’s it folks. After a long time of being away from Herzelia, Aya and I are heading south for the weekend. CYA.
