Today I sat with a friend (let’s call him Joe), who just switched from a job in QA to programming, and passed on to him some of the little tips and tricks I learned over the years. I’m sharing it here because I thought it could be useful to other people that are new to programming. The focus of this post is C#, but analogous tools and methods exist for other languages of course.
Refactorings (A.K.A Resharper)
(This is just a short introduction. I recommend the book Refactoring: Improving the Design of Existing Code as further reading)
As I’ve written here before, I just love Resharper. It is the best refactoring tool for C# I know of (even though it’s a bit heavy sometimes – make sure to get enough RAM and a strong CPU). Joe asked me about a C# feature called partial classes. He said his class was just too big (4000 lines) and becoming unmanageable, and he wanted some way to break it to smaller pieces. He also said that at his workplace, they lock the file whenever anyone edits it, because it’s very hard to avoid merge conflicts on such huge files.
I was happy he wanted to simplify and clarify his code by splitting the file, but the way he thought of doing this was the wrong way.
Tip I: Single Responsibility and Information Hiding
You should strive to minimize the information you require at place in your program. Joe had dozens of unit tests, which all derived from a single base class that contain methods required for all the tests. In a second look, we saw that some of the methods were in fact only needed by some subset of the tests, that were actually logically close.
To solve Joe’s problem, we created an intermediate class, which inherited from the common test base class, and changed these classes to inherit from the intermediate class. We then used Resharper’s Push Down Member refactoring, which removed the methods from the test base class into the intermediate class. No functionality was changed, but we removed code from the huge 4000 lines class! By continuing this process, we can break down the huge class into separate related classes with Single Responsibilities, and no class would have access to uneeded information (like methods it doesn’t care about).
Tip II – Duplicate Code Elimination
I believe the world of software would be a better place if people were not allowed to Copy-Paste code more than a few times a day. Many coders abuse this convenient shortcut and thus create unmaintainable code. The effective counter-measure to the Copy-Paste plague is elimination of duplicate code.
I saw in Joe’s long file code that looked similar to this:
alice = Configuration.Instance.GetUsers(“alice”);
bob = Configuration.Instance.GetUsers(“bob”);
charlie = Configuration.Instance.GetUsers(“charlie”);
diedre = Configuration.Instance.GetUsers(“diedre”);
…
Even though this is a rather simple example of code duplication, I strongly believe even such minor infractions should be dealt with. Every line of the above code snippet knows how to obtain users from the configuration. This knowledge has to be read and maintained by developers. Instead, why not get all the “user getting” code into one place and let us simply write what we want to do, instead of how?
To solve this, I use one of these two techniques:
Extract Method, Tiger Style
- Choose a single instance of duplication, and locate any parameters or code that is not the same among all the instances of the duplicated code. In our examples, the username (and the assignment variable) are the only two different things between the four lines of code.
- For every such parameter, use Introduce Variable. The end result of this phase should look something like this:
string username = “alice”;
alice = Configuration.Instance.GetUsers(username);
bob = Configuration.Instance.GetUsers(“bob”);
charlie = Configuration.Instance.GetUsers(“charlie”);
diedre = Configuration.Instance.GetUsers(“diedre”);
…
- Now, use Extract Method on this code (the first line in our example). This creates a new method that I would call GetUsers, that simply gets a string argument username and reads it from the configuration.
- Perform Inline Variable on the variable you created in step 1.
- Now, change all the other instances to use this new method and delete the redundant code.
The end result looks like this:
alice = GetUsers(“alice”);
bob = GetUsers(“bob”);
charlie = GetUsers(“charlie”);
diedre = GetUsers(“diedre”);
Another way to achieve the same refactoring is Crane Style (I’m just enjoying using kung-fu styles here because I saw Kung-Fu Panda not too long ago :). You can use immediately without creating the temporary user, but then you get a method that specifically returns the username for “alice”, which is not what you wanted. Nevertheless, this method can be refactoring by applying Extract Parameter on “alice”, netting us the same result.
Of course these two examples do not begin to cover the myriad of ways you can and should refactor the code. What’s important is that you always keep an eye out on how you can make your code more concise, which in turns leads to readability and maintainability.
Tip III: Code Cleanup
Resharper sprinkles colors to the right of your currently open file. Every such colored line is either a compilation error (for red lines), or a cleanup suggestion. Go over such suggestions and hear what Resharper has to say (in the example below it seems nobody is using the var xasdf, so a quick alt-Enter while standing on it will remove it).
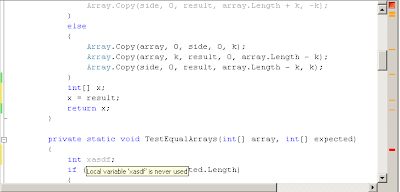
Another thing which you should do is define and run FXCop
rules to perform a deeper analysis on your entire project/solution and spot potential problems.
Source Control
Tip IV – Use Source Control
I almost left this out as this goes without saying, but properly using source control can probably save you more time and money than all the other tips (or cost you if you don’t use it). The best source control tool I know of for Visual Studio is of course Team Foundation Server, as it has the best integration with the IDE. Other tools are possible, but you have to have a good reason for choosing something other than TFS (One good reason might be cross-platform development and the desire to keep all your code base in a single repository).
Automatic Unit Tests
At Delver, we use NUnit to write unit tests. In past projects I’ve used Visual Studio’s built in test tool, but I found NUn
it to be slightly better, mainly due to the integration with Resharper. Resharper adds a small green button next to every test, and allows you to run your test directly from there instead of looking for the “Test View” window. Tomer told me just last week that he uses a keyboard shortcut for running tests, but for me, this is one shortcut I don’t think I’ll bother learning (the brain can only hole so much).
Another benefit of NUnit is that it runs the test suite in place in your current source folder, instead of copying everything aside to a separate folder like Visual Studio’s tool (this used to takes me gigs of space of old unit test sessions which were rarely if ever used).
Tip V – Write Autonomous Unit Tests
Back to Joe, he has a few tests that don’t work right out of the box. Before running tests, he has to manually run a separate application used by his test suite. As his project contains hundreds of tests, I would love seeing this added as an automatic procedure in his TestInit() method. Automating a manual operation, besides saving time for developers, enables you to:
Tip VI – Use Continuous Integration
Tests that nobody runs are no good. Tests that are run once when written and then forgotten are only slightly better. By the same logic, tests that run all the time are the best. Pick and use a Build Automation System. I wrote before about our chosen solution, TeamCity, and to sum it up – we’re extremely happy about it. TeamCity runs our tests on every commit, on multiple configurations and build agents, and helps us detect bugs faster.
Know thy IDE
Visual Studio is one powerful tool (not belittling java IDEs like IntelliJ and eclipse which in many cases are better). Learn how to use it’s features to your advantage:
Tip VII – Edit And Continue
Suppose that while debugging, you found a bug. You can edit the code, save, and continue the debug session without losing the precious time you took getting to this point.
Tip VIII – Move Execution Location
See the little yellow marker that signifies the current location inside the program being debugged? This arrow can be moved! It took me quite a while to discover this (actually heard about it from Sagie), but if you take and drag this arrow, Visual Studio will rewind or “fast forward” your execution to the desired point. None of the code gets executed, you just skip to where you want to go. Excellent for going back after executing a critical method, and rerunning it as many times as you wish.
Tip IX– Use Conditional Breakpoints
Don’t waste your time waiting for some specific value to appear in the watch for an interesting variable – set your breakpoints to stop only when the desired conditions are met (right-click on the red breakpoint circle and choose “Condition”).
Tip X – Attach to Process
Got a bug that only happens on production machines? You can attach your IDE to any running process (preferably one that is compiled in debug mode), and debug away. You can also programmatically cause a debugger to attach using System.Diagnostics.Debugger.Lau
Tip XI – Use The Immediate Window
The Immediate window is a great tool for executing short code snippets solely for debugging. You can place a breakpoint inside a method you wish to debug, and then call the method directly from the immediate window (saves you from doing this through Edit And Continue)

